Microservices are awesome. We know this because of all the success stories that are circulating lately. The news is full of such stories, of people taking large, monolithic codebases, breaking them up, adding HTTP APIs and enjoying all the benefits.
As with all fashionable practices, it starts out innocently enough, someone tries it, it works out very well for them, they present it in an eloquent way that outlines all the advantages of the new practice, and everyone is excited and eager to try it out. Soon, you have a deluge of articles saying how well it works, and how more people tried it with great results. What you don’t hear, though, is the cases where it didn’t work, simply because people aren’t as motivated to write about their failures.
Before I continue with the article, I want to clarify that I’m not saying that microservices don’t work. As with everything, there are advantages and disadvantages, so I’m going to get into a bit of detail about the latter, since the former have been so thoroughly covered.
Cargo cults
You’ve probably heard the phrase “cargo cult” by now. Metaphorically, it refers to trying to succeed at something by doing things you’ve seen other successful people do, although these things are either unrelated to the success or insufficient on their own.
In this context, it refers to implementing microservices because all the cool kids are doing it, without regard to whether it’s appropriate, or without actually doing the things that led to microservices being successful in the first place. As with any other tool, it’s good to know the strengths and weaknesses with microservices before you use them.
Strengths
Let’s start with the strengths.
- Scalability: This is the big one. Since microservices are small and self-contained, they can be placed on their own server, if the need arises. They can be load-balanced, sharded, or configured in any way that makes sense for your application.
You can also decide where to store the data on a per-service basis, using the datastore (and even programming language or technology) that makes the most sense for each use case. - Cleaner architecture: Every service has clearly-defined boundaries, which are usually inviolable. Gone are the days of accessing private data because of convenience, every service is now clearly separated behind an API and nothing else can be accessed.
- Independent deployments: Since every service is separate, it’s easy to deploy them as needed, even multiple times a day. This can also lead to better uptime.
- Smaller codebase: Since the codebase is smaller, it’s also easier to understand. The purpose of each service is clearly defined, and so is its interface, so it’s much simpler for someone to quickly read and understand, and thus modify, extend and maintain.
Weaknesses
- Complexity: You immediately increase the things your servers have to do tenfold. You’re sticking intermediate layers in-between them, you’re putting a network all up in your stack, you’re increasing your total deployment and ops workload by an order of magnitude and you increase the amount of services you need to monitor by many tens of times.
There’s also a bunch of code necessary to marshal/unmarshal data from and to the other services, and, while it’s typically not a large amount, there are always dragons in there. - Overhead: All these disparate data stores, data transformations and network calls come with a pretty hefty premium. Personally, I’ve seen slowdowns on the order of 1000% when moving to microservices (yes, ten times slower).
- Data segregation: Since all your data now lives in different data stores, you’re responsible for relationships between data. What would be a simple cascading delete in a monolith is now a complicated symphony of dependencies, calls and verifications. This is pretty much the same as if you’re using a non-relational data store, so if you have experience there and are good at managing it, you’ll have no problems.
Critical evaluation
As we see above, microservices have some pretty big advantages, but they also come with big disadvantages. In terms of project size, all sizes will benefit from the cleaner architecture and the smaller codebase per service, but all sizes will also be hit by the data segregation and complexity penalties.
Smaller projects will be hit particularly hard by the overhead, but large projects will benefit very much from the scalability and the independent deployments, as it will give them flexibility and a lot of leeway in adding processing power to their stack for serving increased workloads.
Should you use microservices?
Given the above, it seems clear that smaller projects will benefit the least from a microservice architecture. However, they can still reap the benefits of the cleaner architecture and smaller codebases, right?
Not so fast. There’s nothing that prevents monoliths from reaping these benefits as well, while also enjoying all the benefits of a monolith. In fact, this is exactly how a well-architected monolith should be structured, as semi-independent modules or libraries, with clearly-defined interfaces. The problem is that this takes discipline, whereas a microservice-based architecture enforces this at the system level.
It seems reasonable, therefore, to ask yourself and your team this question: Can you trust yourself so little that you need to incur the (rather large) deployment, instrumentation and speed penalties to ensure separation of concerns? In most cases, there are other things you can do, such as implementing clear and strict interfaces for the modules to communicate with each other, create rules about what can and cannot be called outside of modules and how, and use tooling to help you stick to them.
An easy way to decide
To help you navigate the labyrinthine maze of questions and consideration when it comes to deciding whether you need microservices, I’ve created a helpful flowchart (you’re welcome). Here it is:
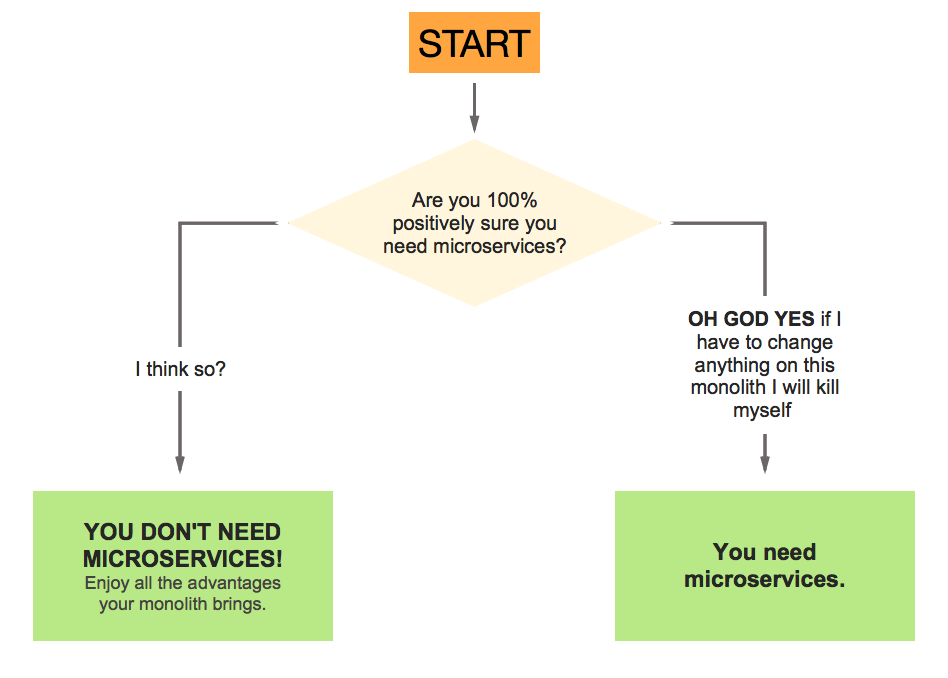 This flowchart will answer all your microservices questions.
This flowchart will answer all your microservices questions.It’s only slightly tongue-in-cheek.
Epilogue
To sum up, the biggest advantage a microservice architecture brings to the table that is hard to get with other approaches is scalability. Every other benefit can be had by a bit of discipline and a good development process. On top of that, by choosing a monolithic approach, you’ll reap the rewards of reliability, easy deployment and monitoring, and speed. As long as your monolith is properly architected, it will be easy to later on split the bottlenecks off into their own services, potentially rewriting them in some other language, if that’s what’s required.
Verily, verily, I say unto thee, do not start out with microservices just because the cool kids are doing it, they’re the complicated way that you don’t need in the beginning. Enjoy the ease of development and agility of deployment that a single new app brings, and, when your business has been proven and growing and you can’t find servers big enough for it, only then split out parts of your infrastructure into their own services, connected by HTTP or a messaging queue.
To take part in the ensuing flame war, you can find me on Twitter or just comment on this page, lest there be collateral damage.