I’ve been making web apps since 2003, which means that I’ve been doing this for fourteen years now, or it means that I can’t count. So, there are few people more qualified than me to tell you this:
The web is crap.
If you disagree with the above statement, you spent more than $1000, less than two years ago, on the device you’re currently reading this on, so websites feel fast to you. There are many factors that make the web crap, but today I’d like to talk about one of them:
Web analytics.
A brief retrospective
The web was created in, like, the nineties, and was initially envisioned as a lightweight system to share text and cat photos. So far we’ve achieved only one of those goals.
As the web started to develop, and more and more people started to join in, more and more people started to produce and consume content. Naturally, human avarice and vanity led to people wanting to know how popular their content was, which, in turn, led to people creating and using those awful counters that showed you how many visitors had been to your website, and reminding you that it was still the nineties.
Those counters were the granddaddy of modern analytics. As the number of people with money to spend on the web grew, so did the desire to make them spend more money, and thus the need to manipulate them more effectively into parting with their gold. A central tenet of psychological manipulation is “know thy victim”, as manipulation gets easier the more data about the target you have, so analytics systems kept becoming more and more sophisticated to extract more and more money from unsuspecting users.
Finally, we are now at the point where the web has somnambulated into being a full-blown application delivery platform, except both the “application” and the “delivery” parts are hacked together with chicken wire and duct tape, and analytics are the cherry on top.
The current state of affairs
The current state of affairs is as encouraging as you’d expect after having read the previous paragraph, i.e. not at all. Almost all analytics software tries to extract as much information about the user as possible, in the hopes that, at some point, an intern will stumble upon a meaningful correlation between a user’s mouse cursor color and a preference for chicken nuggets. This information is retained indefinitely, resulting in a privacy nightmare for users, who end up with their cursor color and complete browsing histories in the hands of unscrupulous third-party vendors.

Have you ever noticed how much Javascript a Twitter button loads? Have you ever wondered why a Twitter button needs to load an entire iframe in order to display what is literally equivalent to an image with a link? It’s because every time you load a page that has a button or element from Twitter, Facebook, YouTube, Google, etc, that company makes a note of which page you visited, when, who you are, what your browser was, where you were when you visited, etc. Facebook literally has a list of sites that you, John Smith, visited, even if you visited them completely outside Facebook, without clicking on any Facebook posts or links at all, just because there was a “Like” button on them.
Yes, Twitter knows all the porn you ever watched, because you were logged into Twitter and YouPorn has a “Tweet” button on its pages that does pretty much exactly what this link does, minus the tracking of your fetishes.
Not only that, but it slows webpages to a crawl. Websites load thousands of lines of code, which takes many seconds to load and takes up a bunch of your memory to compute, just to send your personal information back to the site. Just take a look at how much data The Verge loads just for trackers and spyware, and that’s the rule, not the exception.
Countermeasures

Due to this gross invasion of privacy, users have begun using ad blockers en masse, with some browsers shipping with ad blockers by default. These ad blockers range from incidentally blocking analytics trackers to specifically blocking only privacy-violating trackers, and doing a very good job at it, too.
This arms race means that the more data advertisers want to collect about the users, the less inclined the users are to tolerate it, and the less data the advertisers end up getting. This, of course, makes analytics less accurate, since they underestimate the number of people who visit websites, to the dismay of everyone.
Most blockers (mainly ad blockers) work by preventing connections to various well-known ad-serving domains, but Privacy Badger works by specifically blocking only services that track you (as it can accurately tell which service is tracking you). Users nowadays run a combination of both, as they provide great benefits: They get rid of ads, increase privacy, and make websites much, much faster. Why wouldn’t someone use them?
Solutions
What sort of cranky curmudgeon would I be if I didn’t offer any solutions to the problem, after such a long-winded introduction? The right kind, of course, but I’m going to talk about some solutions anyway.
One good aspect of the situation is that incentives are somewhat aligned. By virtue of using the service, a user gives a minimum amount of information (which page was accessed, where the user came from, where the user is roughly located), and the publisher can use that to perform some analysis. All that’s necessary is for publisher to approach the problem the right way.
Server-side log analysis
A better alternative to client-side analytics (i.e. loading a small (but in reality quite large) piece of code into the user’s webpage to get as much information about the user as possible) is server-side analytics. Server-side analytics only uses analysis of the actions that the user has taken, and does not inject any tracking code into webpages. This makes webpages smaller, faster, lighter, and is not as intrusive to the user’s privacy.
The downside to the publisher is, of course, that some aspects of tracking are less effective. In particular, since server-side analytics do not inject any tracking code, they are less effective at detecting whether a user has just come to the website for the first time or whether they are returning to it. On the other hand, they are more accurate on the number of visitors.
GoAccess
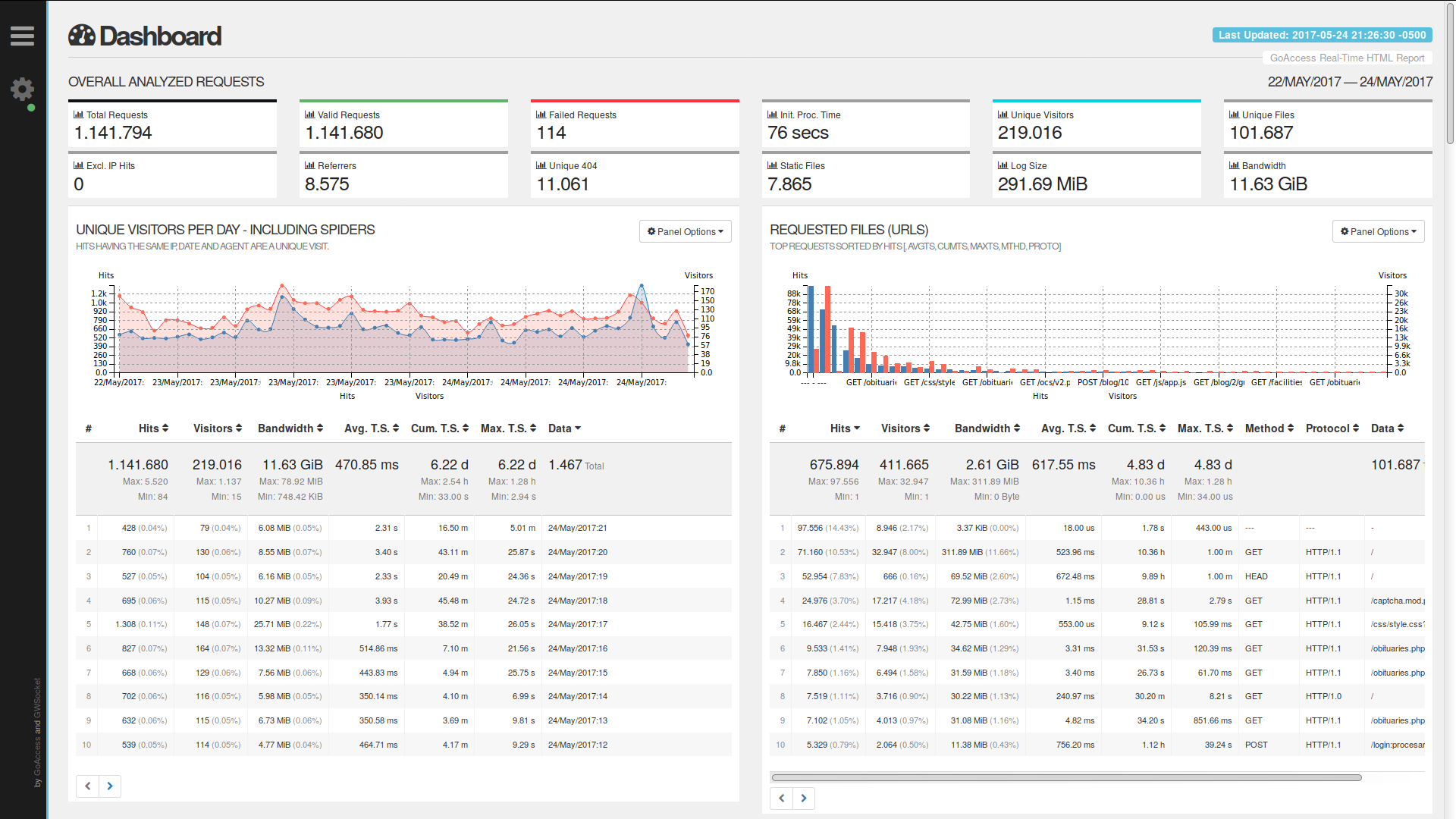
The best (and pretty much only?) such software I’ve found is GoAccess. GoAccess is a fantastic piece of software that analyzes your webserver log entries very quickly and stores them in its database, either generating HTML reports that you can open in a browser, or displaying reports in a curses window in the console. The latter mode is a bit hardcore, but the former is very detailed and very readable.
Of course, the report won’t contain things like screen resolutions, click heatmaps, or scroll patterns, but it’s fast, can give you statistics from before it was installed, and, more importantly, incurs no additional overhead in page load times or performance for the user. It also does all the usual weeding out of bots, detects return visitors, and generally provides a good, if basic, analytics experience, which may not be suitable for publishers with dedicated marketing teams, but is more than adequate for the average website.
Another benefit for the publisher is that, because it analyzes HTTP requests, it cannot be blocked by the user, so its reports are as accurate as possible. Personally, I have seen around a 30% discrepancy between Google Analytics and GoAccess (Google Analytics reports 30% fewer visits than GoAccess), which I assume is due to the high usage of ad blockers among the people that read my website.
If you have a website that you want to use analytics on, you’d ideally add GoAccess to your crontab or logrotate config, and it would read each log as it is being rotated and add them to its database, so you could view accurate historical data for any point in time. Unfortunately, the cron method doesn’t work properly right now (although the logrotate method should), because of an open issue which has GoAccess double-count entries if you run the import twice.
Generally, though, GoAccess is a great alternative to client-side tracking, and I switched to it exclusively (until I changed hosts and that became impossible, cough).
Piwik
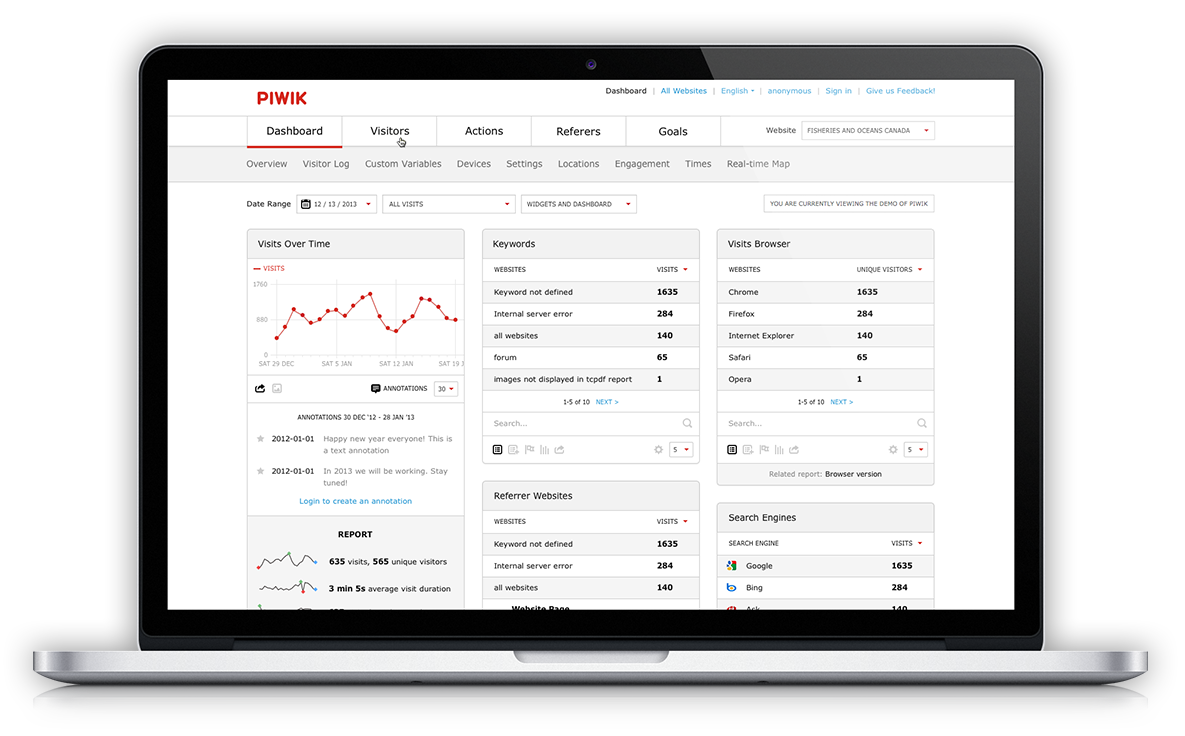
Piwik isn’t like GoAccess, in that it’s not exclusively server-side. It’s more of an open-source, self-hosted Google Analytics alternative, but it has various modes of operation. It includes a log analyzer, but you can also set it to serve a “tracking pixel”, which is a small image that gathers basically the same information as log analysis, and similarly cannot be easily blocked if served from the domain of the site.
Piwik does also include a full-blown JS tracker, but I don’t recommend that for the reasons stated above. Even that, though, is better than Google Analytics, as the data stays with the publisher and doesn’t get shared with Google, only to stay with them forever and ever.
Social button alternatives

I find the social buttons particularly egregious, especially Twitter’s and Google+’s (good thing nobody ever uses the latter, at least), because they do nothing for the user that a simple link wouldn’t. Publishers like them because they make it easy for people to share the content, which makes the latter visible to more people, which means more viewers, which means more ads, which means more money. That’s why they charge a hefty fee for their use, not in currency but in tracking and slowness.
Here you’ll notice my hypocrisy in having social buttons at the bottom of this post, but you may also notice that they aren’t actually social buttons, and yours can not be, too! They’re just static images, each with a link to a URL that will allow you to share this article on each service.
If you want to replace the Twitter, Facebook and Google+ buttons on your site with non-tracking, lightweight alternatives, here’s how you can do that. Just use the following HTML and the result will be almost indistinguishable (except your site will be quite a bit faster).
For the Twitter button, a simple link to the URL below is enough:
<a href="https://twitter.com/intent/tweet?text=Look,+ma!+No+tracking!&url=https%3A//www.stavros.io/&via=stavros" target="new">Twitter button</a>
Same for Google+:
<a href="https://plusone.google.com/_/+1/confirm?hl=en&url=https%3A//www.stavros.io/" target="new">G+ button</a>
And Facebook:
<a href="https://www.facebook.com/sharer/sharer.php?u=https%3A//www.stavros.io/" target="new">Facebook share button</a>
These load almost instantly, use almost no extra memory or CPU and leak no information about your users to any third-party site.
EDIT: User nachtigall on the Hacker News comments thread gave me a great tip: Shariff replaces your social buttons with simple, non-tracking links, much like my code above. I will integrate that to this website as soon as possible, as it’s a fantastic idea. User Raphmedia linked me to SocialSharePrivacy, which only loads the sharing scripts on-demand, preventing them from tracking the user unless specifically used.
Epilogue
As you’ve surmised, I’m very disappointed by the direction the web has taken. However, that’s only because I think things don’t have to be this way, and I’m happy to see that things are changing for the better. Ad blockers are forcing publishers to rethink their business models and to reduce the amount of tracking they do, browsers implement features that make it harder to violate users’ privacy, and frontend tooling is getting better and making it easier for developers to create lighter websites.
I think things could be better, though, which is why I’m writing this, and why I’m trying to create an informational site with resources for making the web lighter. There’s no reason why small websites should embed Google Analytics, only to use 3% of its functionality, or use the bloated Disqus comments when there exist lightweight, open-source alternatives like Isso, which I’m using here. I would encourage you to get rid of Google Analytics1 and use one of the alternatives above, if you can. For event tracking, doing it on the server is much better for everyone, as the user’s experience isn’t affected by it at all, and you usually don’t need any of the extra information anyway.
If you have any recommendations or agree/disagree with what I’ve written, please leave a comment or tweet to me. I’m especially interested to hear if you like and have switched to any of the alternatives above.
Thanks!
You might notice that, as of this writing, I’m hypocritically using Google Analytics on this website. That’s because I recently moved to a static site generator and CDN host, which doesn’t give me access to visitor logs. If you know of a better (non-self-hosted) alternative, please leave a comment and tell me about it, I would very much like to know.↩